リソース
一覧
RNN・LSTM
Seq2Seq
- Cho al. 2014 Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- Denny Britz, Deep Learning’s most important ideas
- Visualizing the Seq2Seq model and attention
Transformers
- Seattle Applied Deep Learning: LSTM is dead. Long Live Transformers
- Illustrated Transformer(まずはこれ!本当に素晴らしいアニメーション!!)
HuggingFaceで実装のノートブック
背景
NLPの記事・論文を読むと、Attention(アテンション、注意力メカニズム)がどうしても現れる。Attentionとは、一体なにでしょうか?このポストでアテンションについての理解を深めようと思います。そして、PyTorchで実装も試してみると思います。
基礎:RNN・LSTM
RNN
人間が「昨日、りんごを食べました」のような文を読むと、「食べました」を読むと、「りんご」についてを覚えるのが当然です。しかし、denseとcNNのような構造が「その前に来た」内容を覚えることができません。
その問題を克服するため、今回の出力が次回の入力にして、「また現れる(Recurrent)」という構造が作られていた。
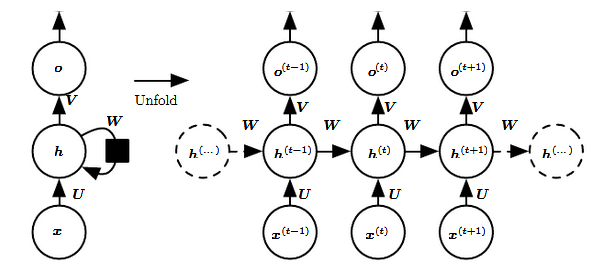
また、0からT個の入力を考えると、上記の通り、ループを展開することができます。また、
- U: 入力からユニットまでの重さ行列
- V: ユニットから出力までの重さ行列
- W: ユニット(t-1)からtの重さ行列
- U, V, Wはどちらも全部インプットにシェアされている
- Hiddenレーヤー・ステートh(t) = f(U x(t) + W h(t−1)), fは非線形関数(tanh, sigmoid,ReLU)が使われている
ある入力Nを見ると、前の入力(t-1), 入力(t-2)などを考えられることはものすごくいいですが、実際に「I grew up in France… I speak fluent{}」の場合、「…」の長さが一つの段落でもありえます。もちろん、直前も言葉を見ると、言語の話だとわかっていますが、「フランス語」で空白を埋めるためにもっと前の内容を覚える必要がある。
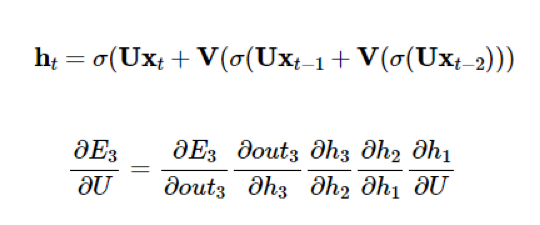
しかし、RNNが(t-k)、kが大きい数値の入力を覚えようとすると(文の場合でしたら長い文の最初のこととか)問題が発生してしまいます。なぜなら、Backpropagationで偏微分を計算すると、その微分が消えてしまうため、Gradient Descentでパラメーターの最適化を行うことができなくなってしまいます。
LSTM
普通型のRNNの問題を解決するため、LSTMが使われている。LSTMとは、RNNのサブタイプのであり、ただしユニットのLSTM-Cellが少し複雑になっています。

このようなLSTMセルが、なぜRNNの問題を解決できるというと、それぞれの要素を詳しく見る必要がある。まずは、LSTMのセルの中、以下の関数がよくつかわれている
- sigmoid関数:この関数は(0, 1)を出力しますので、スイッチのような存在です
- tanhこの関数は、(-1, 1)を出力しますので、方向性を与え、正常化を行う。
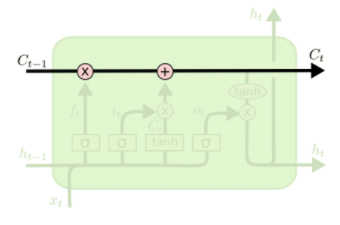
まずは上の直線を見ましょう。この線によると、シーケンスが大体変えずに次のセルに行けます。このため、離れているセルでもお互いに影響することができます。
次に、「忘れるゲート」を見ましょう。この部分ではsigmoid関数でht-1を覚えるか忘れるかと制御できます。
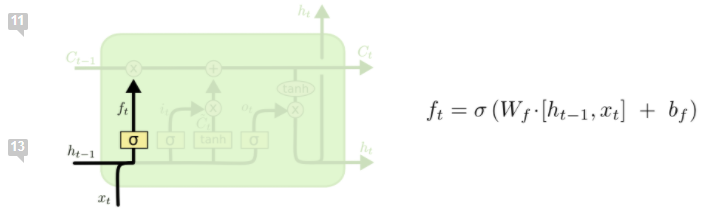
次は「新しい内容ゲート」です。この部分ではまずsigmoid関数で「アップデートしたい」フラグをつけて、そしてtanh()でアップデート値を決める。次にこの重さを掛ける。
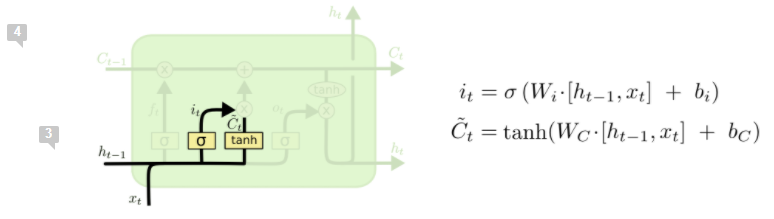
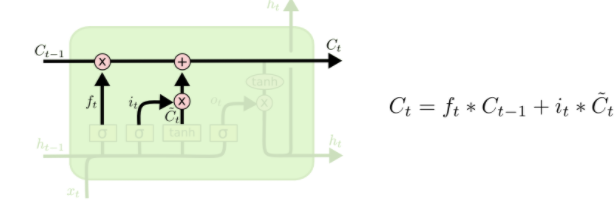
そして、フロー部分をアップデートする必要がある。ht-1の値はsigmoid()でスイッチで制御されていますので、*を使う。新しい内容は既にsigmoid()にフィルターされましたので、+を使って影響を入れる。
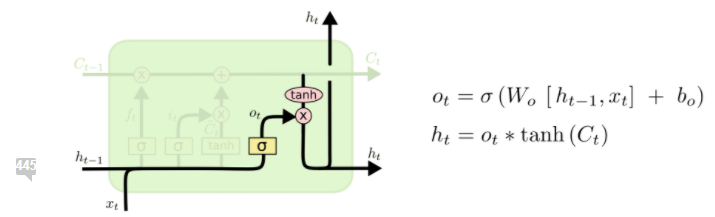
最後に、セルのhiddenステートをアウトプットを計算する。まずはアップデートされたフロー(つまり、このセルを入力を含む値)をtanh()で正常化し、そして前に決められたフィルターでまたフィルターし、最後の出力を計算できる。
また、LSTMセルに基づく、変種のGRU、”peephole”もいろいろあります。
アテンション登場:Seq2Seq構造
Seq2SeqまたはRNN Encoder-Decoder:Cho et al.(2014)とSutskever et al. (2014)
Seq2Seqとは、入力と出力がそれぞれ一つのRNN系のニューラルネットワーク(LSTM・GRU)であり、機械翻訳のために使われていた構造である。
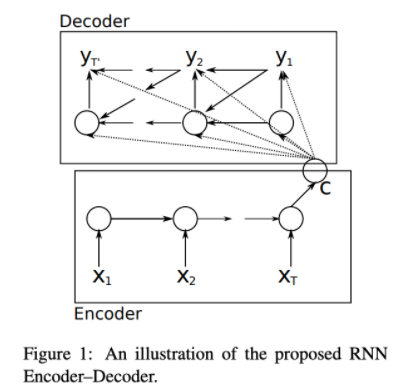
例えば、英語の原文をフランス語に翻訳しようとする時、まずはエンコーダーが英文のベクトルを読み込んで、下記の図通りHiddenステートを計算し、エンコーダーのHiddenステートCが英語文の概要となっている。
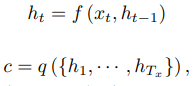
次に、デーコーダーがCも入力とし(エンコーダーに比べると入力)、自身のHiddenステートを計算することができます。そして、下記通り、関数g()によるフランス語の確率ベクトルを生成する。
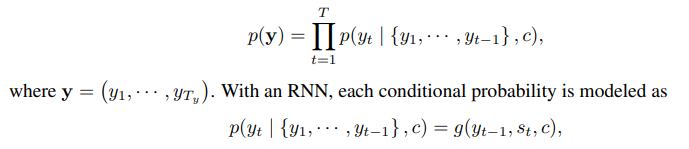
こちらで注意していただきたいのは以下の点:
- 普通型のSeq2Seqモデルにおいて、ベクトルCのサイズがハイパーパラメータとして決まっている。
- 英語文のベクトルとフランス語のベクトルの長さは変わってもいい(Cと違う!)
Seq2Seq改善:Attentionメカニズム Bahdahanu et al. (2015)
Bahdahanu et al.が「Seq2Seqの欠点はサイズが決まっている概要ベクトルCである」と主張しました。その理由は、Seq2Seqを使うと、短い文でも長い文でも同じ長さの概要ベクトルに詰めないといけなくて、訓練セットではめったにない長い文をエンコーダーで「概要」を生成すると、情報ロースが発生してしまうからです。この問題を克服するため、「出力を入力に揃える」、つまり、文のある部分を注意するというメカニズムをニューラルネットワークの構造に入れました。
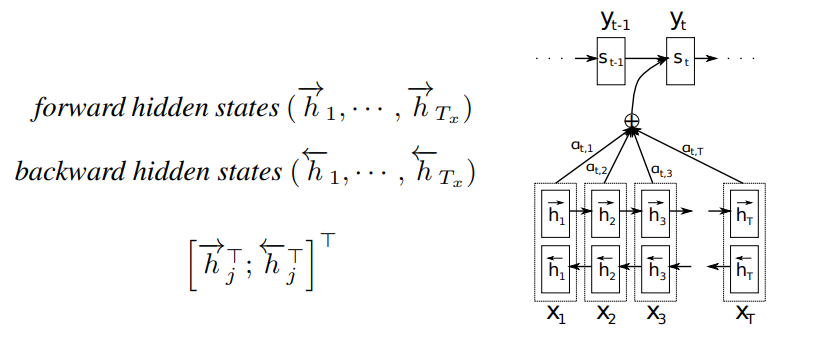
次に、概要ベクトル(この論文の場合はContextベクトルと呼ばれている)を計算すると、次の式を使う。

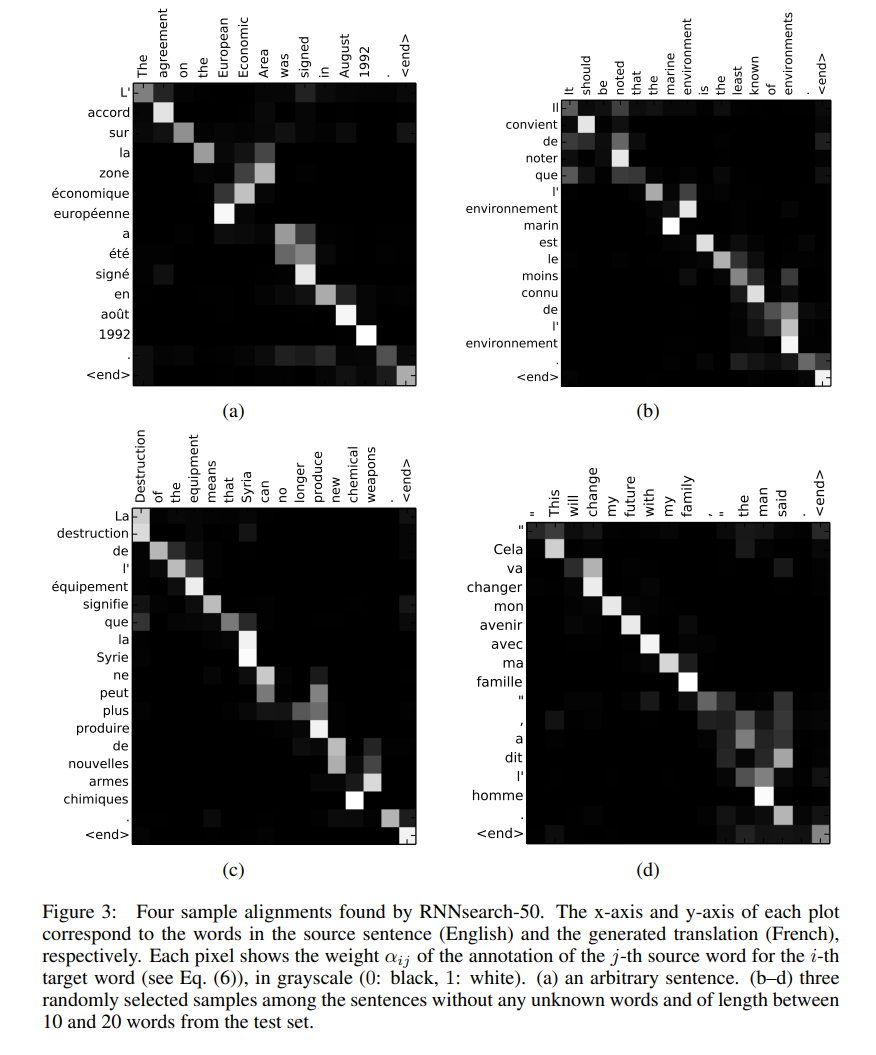
この中、一番面白いのはa()。a()はfeedforwardのニューラルネットワークである、直接にモデルと一緒にBackpropを使って最適化することができます。このa()の出力eij・aijが、「hjの周り、どのトークンが重要でしょうか?」という質問に答えますので、これは「注意力」と呼ぶ理由となります。下記のヒートマップでは、その注意力を可視化しました。このヒートマップの中、行は出力であり、「Query」または「Q」と呼ばれている。列は入力であり、「Key」または「K」と呼ばれる。
最後に、出力の確率を計算すると、一つのCではなくそれぞれの出力siに対するciを計算し確率を推定する
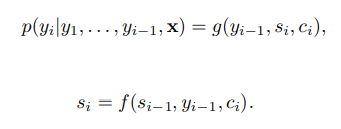
著者によると、このモデルの利点は二つあります:
- A() というニューラルネットワークにより適応性のあるアラインメント。つまり、A()の重さにより「どのトークンを重視すべきか」が決められる。
- 決められたベクトルCに制限されていないこと。
Transformers Vaswani et al. (2017)
2017年以来、Transformerに基づく構造がNLP・DLの分野に大きな影響を与えました。
その理由は以下となります:
- self-attention(自己アテンション)
- Positional Embedding(位置の把握)
self-attention(自己アテンション)
まずは、Transformer構造を見ましょう:
エンコーダーの部分のかなり複雑であり、しかしキーな部分はその真ん中の”Multi-Head Attention”です。
Transformersにおいて、Self-Attentionとなります。つまり、QueryもKeyも、入力に関わるものである。
QとKを計算しましたら、お互いの「重要さ」スコア(Relevance)を計算するため、内積を取る。
スコアを計算しましたら、下記の図通り、QとKの上に、Kのコピー、Value(V) という行列も使います。個人的な理解なんですが、これはスキップコネクション・LSTMのフロー部分に似ているじゃないかと思います。また、Q, K, V, はパラメーター行列である。
また、コードにおいて、このような感じになります:
# X_in : Tensorリスト:一つの入力のトークン=一つのTensor
def attention(self, X_in:List[Tensor]):
# 1. まずは一つのForループでQ、K、V(パラメーター行列)で入力のEnbeddingベクトルをかける
for i in range(self.sequence_length):
query[i] = self.Q * X_in[i]
key[i] = self.K * X_in[i]
value[i] = self.V * X_in[i]
# 2. QとKと使って、内積によりスコアを計算する
for i in range(self.sequence_length):
this_query = query[i]
for j in range(self.sequence_length):
relevance[j] = np.dot(this_query,key[j])
# Softmaxによりスケーリング
relevance = scaled_softmax(relevance)
# アウトプットを計算、Vをそのまま足す
out[i] = 0
for j in range(self.sequence_length):
out[i] += relevance[j] * value[j]
return out
Multiheadとは、これを何回でもやる。元の論文は8を使いました。アテンションブロックを八つ使って、言語の様々な特徴に集中して勉強できる(文法、語彙など)。「集中」というのは、最初から意識的に決めることではなく
Positional Embedding(位置の把握)
次に、言葉の位置を把握するのはも重要です。
この問題を解決ために、Word2Vecで得られたベクトルに様々な周期の三角関数の値を足して、モデルに「この言葉の位置はどのぐらい」を教える。
結論
これでTranformerのキーな部分、特にself-attention、を理解しました。Decoderは大体同じな構造で、ただし最後logitを出力の語彙の確率に変換するレーヤーがあります。
LSTMのような構造に比べて、transformerは以下のメリットが持っている:
- 訓練しやすい
- 特定のデータセットを使って最適化されたLSTMより汎用性(Transfer Learning)が圧倒的によい。
- 最初の訓練は、レベルされていないデータでもよい。つまり、あらゆるテキストデータが使えます。
- 計算の速さです。Self-attentionにおいて、全てのトークンに対して全ての他のトークンに比べる必要があるので、計算量はO(n2)にある。しかし、LSTMのような構造と違って、並行で計算できますので、GPUの力の利用して速度を上げることができます。
sigmoid()とtanh()のような計算精度が必要な関数を使いませんので、精度が高くないハードウエアでも使えます。
これから実際にHuggingFaceというライブラリーを使って、SOTAのTransformerモデルでNLPのタスクに挑んでみると思います。

